
어텐션 : 정보 중에서 중요한 것에 집중하는 기술
- 우리가 뭔가를 볼 때나 읽을 때 중요한 부분에 집중하는데, 컴퓨터가 그것을 흉내 내는 것
기계가 문장을 처리할 때,
각 단어가 다른 단어들과 얼마나 관련 있는지를 수치로 계산함.
이것을 Attention Score 이라고 함.
--
입력의 각 요소가 다른 요소들과의 관계(유사도)를 계산해서, 중요한 정보에 더 큰 가중치를 주고, 그걸 기반으로 새로운 표현을 만드는 것
기본구조 : Scaled Dot-Product Attention
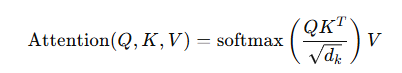
왜 중요한가?
- 위치 무관한 관계 파악 가능 > CNN보다 더 유연
- 멀티모달 입력 처리에 최적 > 이미지, 센서 등
- 문맥 기반의 정보 재구성이 탁월
결론 :
- 어텐션은 정보 간의 중요도 관계를 학습하고 반영하는 방식
- Transformer 모델이 sequence를 다룰 때의 핵심 원리
- 단순히 중요도를 구하는 게 아니라, 그걸 기반으로 정보를 새로 구성하는 게 핵심이다.
어텐션은 단순히 집중이 아니라, 학습 가능한 적응형 커널을 통해 입력 관계를 동적으로 계산하고, 그걸로 정보를 재구성하는 연산이다.
--
Object Detection 의 전통적인 아키텍쳐
- Backbone : 고수준의 feature 추출의 핵심 역할. Ex. ResNet, VGG, MobileNet, Swin Transformer
- Neck (Optional) : feature map의 품질을 개선하기 위해 사용. Ex. FPN, Feature Pyramid Network
- Head : 최종적으로 feature map을 바탕으로 객체의 클래스를 classification 하고, 객체의 위치를 정의하는 bounding box를 예측한다.
- Encoder : 백본에서 추출된 feature를 바탕으로, 인코더는 이 feature들을 더 압축하고, 이미지의 중요한 정보를 캡쳐하는 동시에 차원을 줄인다. 인코더는 일반적으로 여러 convolution layer와 pooling layer로 구성된다. 이 과정에서 activation function이 사용되어 네트워크의 비선형성을 증가시킨다.
- Decoder : 인코더를 통해 압축된 feature map을 다시 확장하여, 최종적으로 원본 이미지 크기의 segmentation map을 생성한다. decoder은 업샘플링 또는 전치 합성곱, tranposed convolution과 convolution layer를 사용하여, 각 픽셀에 대한 예측을 수행한다.
*업샘플링 : 해상도를 높이는 것을 의미, 다운샘플링은 그 반대
어텐션 : 정보 중에서 중요한 것에 집중하는 기술
- 우리가 뭔가를 볼 때나 읽을 때 중요한 부분에 집중하는데, 컴퓨터가 그것을 흉내 내는 것
기계가 문장을 처리할 때,
각 단어가 다른 단어들과 얼마나 관련 있는지를 수치로 계산함.
이것을 Attention Score 이라고 함.
--
입력의 각 요소가 다른 요소들과의 관계(유사도)를 계산해서, 중요한 정보에 더 큰 가중치를 주고, 그걸 기반으로 새로운 표현을 만드는 것
기본구조 : Scaled Dot-Product Attention
왜 중요한가?
- 위치 무관한 관계 파악 가능 > CNN보다 더 유연
- 멀티모달 입력 처리에 최적 > 이미지, 센서 등
- 문맥 기반의 정보 재구성이 탁월
결론 :
- 어텐션은 정보 간의 중요도 관계를 학습하고 반영하는 방식
- Transformer 모델이 sequence를 다룰 때의 핵심 원리
- 단순히 중요도를 구하는 게 아니라, 그걸 기반으로 정보를 새로 구성하는 게 핵심이다.
어텐션은 단순히 집중이 아니라, 학습 가능한 적응형 커널을 통해 입력 관계를 동적으로 계산하고, 그걸로 정보를 재구성하는 연산이다.
--
Object Detection 의 전통적인 아키텍쳐
- Backbone : 고수준의 feature 추출의 핵심 역할. Ex. ResNet, VGG, MobileNet, Swin Transformer
- Neck (Optional) : feature map의 품질을 개선하기 위해 사용. Ex. FPN, Feature Pyramid Network
- Head : 최종적으로 feature map을 바탕으로 객체의 클래스를 classification 하고, 객체의 위치를 정의하는 bounding box를 예측한다.
- Encoder : 백본에서 추출된 feature를 바탕으로, 인코더는 이 feature들을 더 압축하고, 이미지의 중요한 정보를 캡쳐하는 동시에 차원을 줄인다. 인코더는 일반적으로 여러 convolution layer와 pooling layer로 구성된다. 이 과정에서 activation function이 사용되어 네트워크의 비선형성을 증가시킨다.
- Decoder : 인코더를 통해 압축된 feature map을 다시 확장하여, 최종적으로 원본 이미지 크기의 segmentation map을 생성한다. decoder은 업샘플링 또는 전치 합성곱, tranposed convolution과 convolution layer를 사용하여, 각 픽셀에 대한 예측을 수행한다.
*업샘플링 : 해상도를 높이는 것을 의미, 다운샘플링은 그 반대
--
Attention is all you need > 자연어 처리분야인 기계번역에 있어서 방대한 영향을 끼친 논문이다.
- RNN
- LSTM
- GRU
- Transformer : Attention Is All You Need
--
04/08 (화)
*hash table : 자료구조의 핵심개념으로, 빠르게 데이터를 저장하고 빠르게 꺼내기 위한 구조. Ex. 준우 > 103, 딕셔너리의 key와 value 쌍으로 저장하는 자료구조
*context : 입력 데이터의 주변 정보를 의미
*bottle neck : 병목 현상, 시스템 속도 저하를 의미
*dot product : 내적, 성분끼리 곱하고 다 더하는 개념
*CS : Coumpter Science
*토큰 : CS에서는 말, word를 의미. 한 단어 단어를 의미. Ex. "I am a boy" > I, am , a, boy가 토큰에 해당
*Decimal Number : 10진법 숫자를 의미함. 1, 2, 3, 4, 5, , , 100 이런 것들
*Annotation : 데이터에 label을 붙이는 작업을 의미. Ex. 이미지에 개/고양이 label 붙이기, bounding box 그리기가 해당
*Sequence : 순서를 가지는 데이터의 나열을 의미. Ex. 문자열 : "hello"는 h, e, l, l, o라는 문자들이 순서대로 나열된 sequence임. 비디오 : 프레임 이미지들이 시간 순서대로 나열된 sequence임.
*Hyperparameter : 모델이 학습을 잘 하게 도와주는 설정값들을 의미
*Embedding Vector : 단어나 문장을 숫자로 바꾼 벡터. Ex. "사과" > [ 0.12, 0.98, -0.35, 0.56 ]
- 왜 하는가? : 컴퓨터는 숫자만 이해하므로, 딥러닝 모델은 숫자만 처리가능하므로
--
- Attention은 RNN에서 발생하는 bottle neck을 해결하기 위해서 등장했다.
- Self-Attention 에서 주로 세 가지 텀이 많이 사용된다.
- Value
- Query
- Key
- Attention이라는 것은 어떤 state들 중에, 어디를 더 주목해야할지 덜 주목해야할지 가중치를 나타내는 것을 의미한다.
- Query와 Key를 dot product 한 결과값을 attention score라고 함
- 그 후 Softmax 함수를 이용하여 1~0 사이 값으로 만듦 > 이것을 Nomalization이라고 함, 그리고 이 값을 attention weight라고 부름
- MLP에서 가장 중요한 핵심 기능이, Non-linearlity 기능을 부여하는 Activation function임
- Transformer라는 모델이 있고, 그 안에 핵심 구성 요소로 Attention이 들어가 있음
- "Attention is all you need"는 2017년 google이 발표하였음
- Seq2Seq : 하나의 Sequence를 다른 Sequence로 변환하는 모델 구조, Encoder와 Decoder로 구성되어있음
- Ex. decimal number (Encoder) > binary number (Decoder) > decimal number
- Transformer은 기존의 Seq2Seq 구조인 Encoder-Decoder를 따르면서도, Attention만으로 구현한 모델이다.
- RNN을 전혀 사용하지 않았지만, RNN보다 우수한 성능을 보여줌
- 기존의 Seq2Seq 모델 : Encoder가 하나의 벡터로 압축하고 Decoder가 이 벡터를 통해서 출력 Sequence를 만들어 냄
- Multi-head Attention : 여러 개( 2개 이상 )의 Attention을 병렬로 동시에 작업을 수행하는 것
- 각각의 헤드는 다른 시각 관점으로 입력을 해석함 > 그 후 마지막에 합쳐서 풍부한 정보를 만듦 , 집단지성 같은 개념
- Transformer 와 RNN의 차이점
- RNN은 순서대로 값을 입력하나 Transformer은 순서가 없으므로 positional encoding을 통한 순서를 만들어주기 위한, 위치 정보를 따로 인코딩해서 넣어줘야한다.
- Transformer에서 사용하는 3가지 Attention
- Encoder Self-Attention
- Masked Decoder Self-Attention
- Encoder-Decoder Attention
- Self-Attention은 본질적으로 Query, Key, Value가 동일한 경우를 의미. Q = K = V
- Encoder-Decoder Attention에서는 Query가 Decoder의 벡터인 반면, Key, Value는 인코더의 벡터이므로 Self-Attention이라고 부르지 않음