RNN, Recurrent Neural Network
- 대표적인 딥러닝 모델 중 하나
- 시계열 데이터 같은 순차 데이터( Sequential Data ) 처리를 위한 모델로 잘 알려짐
- 순차 데이터의 대표적인 예시 :
- 01 시계열 데이터 : 일정한 시간 간격을 가지고 얻어낸 데이터 Ex. 차량의 주행 속도와 가속도, 주변 장애물과의 거리 데이터를 시간에 따라 기록한 것
- 02 자연어 데이터 : 사람이 말하는 언어 Ex. 차량이 음성 인식을 통해 운전자가 "왼쪽으로 가"라고 말했을 때, 이를 이해하고 적절히 반응하는 과정
- 보행자의 의도를 예측 및 장애물 탐지
- 자동차가 시간에 따라 움직인 데이터를 학습하여 미래의 경로를 예측
--
- YOLO 단점을 보완한 것이 SSD
- Object Detection은 객체 분류( Clasification ) 과 객체 위치 정보( Localization )을 합한 문제이다.
- Object Detection의 동작 방식은 1-stage방식과 2-stage 방식으로 나눌 수 있다.
- 1stage 방식은 객체 분류와 객체 위치 정보를 동시에 해결한다. > 속도면에서 우위, 실시간 탐지에 유리
- 2stage 방식은 순차적으로 해결한다. > 정확도면에서 유리
- YOLO는 1-stage 방식
- R-CNN, Mask R-CNN이 2-stage 방식
- R-CNN, Regions with CNN Features은 하나의 이미지를 넣었을 때 여러 개의 영역으로 잘개 사진을 쪼개어 2000개의 서브-이미지가 되어 CNN을 2000번 통과시킨 다음 클래스를 나눔
- 반면, You Only Look Once, YOLO는 이미지를 한 번만 살피게 됨
- 기존의 R-CNN과는 달리 합성곱 신경망인 CNN을 단 한 번만 통과
- 결과값으로는 각 객체의 bounding box와 해당 객체에 대한 분류 확률 출력
- 영상을 입력했을 때 중앙에 2개의 데이터를 얻게 되는 방식임
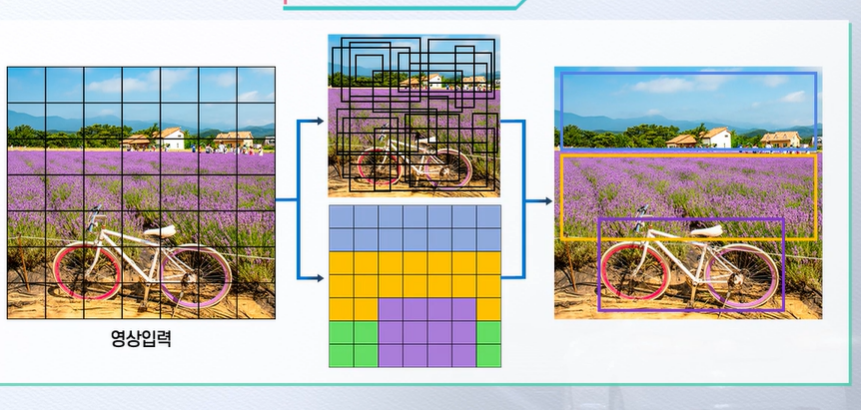
- YOLO의 원리 : 주어진 입력을 여러 개의 그리드 셀로 나누고 미리 설정된 숫자만큼의 바운딩 박스를 그림
- bounding box는 물체가 있을 것 같은 곳을 표시하는 하나의 창문이다.
- Box confidence score이란 bounding box가 해당 물체를 잘 포함하고 있는지와 해당 물체를 얼마나 잘 예측하였는지를 나타내는 지표이다.
- Box Confidence Score = Pr( Object ) * IOU( Intersection Over Union )
- 바운딩 박스 안에 물체가 존재할 확률 * 해당 물체를 얼마나 잘 예측하였는지를 나타내는 지표
- IOU, Intersection Over Union
- 정답을 알고 있는 학습 데이터의 바운딩 박스와 예측한 바운딩 박스가 일치하는 정도를 나타낸다.
- 만일 Bounding Box가 아무것도 없는 배경을 영역으로 잡을 경우
- Box Confidence Score에서 Pr 값이 0 이므로 결과값은 0이 나오게 됨
- Conditional Class Probabilities, 클래스 확률
- 그리드 셀 안에서 탐지된 객체가 어떤 클래스에 속하는지에 대한 확률
- bounding box가 배경을 포함하고 있다면 확률은 0
- 전 세계적으로 잘 알려진 유명한 분류 테스트 데이터셋 > PASCAL VOC
- YOLO의 각 바운딩 박스에서는 위치정보 ( X, Y ), 객체의 크기정보 ( w, h ), Box Confidence Score가 나온다.

- 박스 안쪽에 객체가 있을 것 같다는 확신이 있는 쪽은 박스를 굵게 그림.
- 확신은 Box Confidence Score을 의미

- YOLO의 세 가지 영역
- Pre-trained Network
- YOLO는 구글넷을 이용하여 ImageNet의 1000개의 클래스 데이터셋을 사전 학습한 결과를 Fine-Tuning한 신경망을 포함하고 있음
- 20개의 Convolution Layer로 구성되어 앞쪽에 위치해 있음
- Fine-Tuning(파인튜닝)은 이미 학습된 모델(Pre-trained Model)을 가져와, 특정한 작업(Task)에 맞게 추가로 학습시키는 과정입니다.
- YOLO를 제시한 연구자는 구글넷을 통하여 88% 정확도를 갖도록 사전에 학습 시킴
- Reduction Layer
- 일반적으로 신경망은 구조가 깊을수록 더 많은 특징을 학습해 정확도가 높음
- Training Network
- Pre-trained Network에서 학습한 fearture를 이용하여 Class probability와 bounding box를 학습하고 예측하는 신경망 부분
- YOLO의 단점
- 1-stage 방식이여서 빠르긴한데, 정확도가 낮음
- 하나의 셀에서 하나의 Object만 예측하므로, 겹친 Object는 감지하지 못함
- 하나의 셀에 여러 개의 객체가 겹쳐져 있으면, 하나의 객체만 탐지할 수 있음
- Ex. 하나의 셀에 자동차가 여러 대 겹쳐있을 때, 하나의 자동차만을 탐지
- 작은 물체들은 잘 잡아내지 못함
- SSD, Single Shot multibox Detector
- YOLO의 한계점을 극복하기 위해 개발
- YOLO보다 향상된 정확도와 속도가 특징
- Pre-trained Network
'**Autonomous driving tech. > *Learning' 카테고리의 다른 글
| 자율주행 01 (1) | 2025.02.28 |
|---|---|
| 자율주행과 인공지능 03 (0) | 2025.02.28 |
| 자율주행과 인공지능 01 (0) | 2025.02.26 |
| [자율주행제어 이론 및 실습] Feedback with Feedforward term, ACC( Constant Time Gap Strategy ), HILS (0) | 2025.02.04 |
| [자율주행제어 이론 및 실습] Learning 06 Feedback & Feedforward control (0) | 2025.02.01 |